
長く間が空いてしまいましたが、実は毎日コツコツと記事を書いている怠惰人間です。ブログを作るにあたって、ブログの構成やNeuralNetworkの内容について書く順番決め、プログラムの作成とデバッグと意外と時間がかかって驚いています。さらに最近は、統計学について再度学び直したかったり、A*アルゴリズムなどの古典的?な人工知能のアルゴリズムも記事にしたかったりとやりたいことが頭の中でいっぱいで記事の完成が遅れてしまっています。申し訳ないです。
さて、今回の記事ではNeuralNetworkの出力の多層化を行っていきたいと思います。今回の内容はかなり薄っぺらいですが、次回の記事への重要な布石でもあります。では、本編に行きましょう。
Neural Networkの出力多層化
今までのニューラルネットワークでは、多数の入力に対して1つの値を出力を行うだけでした。しかし、現実で使用されているニューラルネットワークでは、多数の入力を受け取って多数の出力をすると言うことを行なっています。これができると様々なことが可能になりますが、今回はその点には触れずにニューラルネットワークの出力を多層化することだけに焦点を当ててやっていきましょう。
では、どのようにしてニューラルネットワークの式を多層化するかですが、これはとても簡単なことで、重みにベクトルではなく行列を入れるだけです。実際に式を使用して確認してみましょう。
$$
\left(
\begin{array}{c}
a_1 \\
a_2 \\
\vdots \\
a_n
\end{array}
\right)
=
\begin{eqnarray}
\left(
\begin{array}{cccc}
\omega_{ 11 } & \omega_{ 12 } & \ldots & \omega_{ 1n } \\
\omega_{ 21 } & \omega_{ 22 } & \ldots & \omega_{ 2n } \\
\vdots & \vdots & \ddots & \vdots \\
\omega_{ m1 } & \omega_{ m2 } & \ldots & \omega_{ mn }
\end{array}
\right)
\end{eqnarray}
\left(
\begin{array}{c}
x_1 \\
x_2 \\
\vdots \\
x_n
\end{array}
\right)
+
\left(
\begin{array}{c}
b_1 \\
b_2 \\
\vdots \\
b_n
\end{array}
\right)
=
\omega x + b
$$
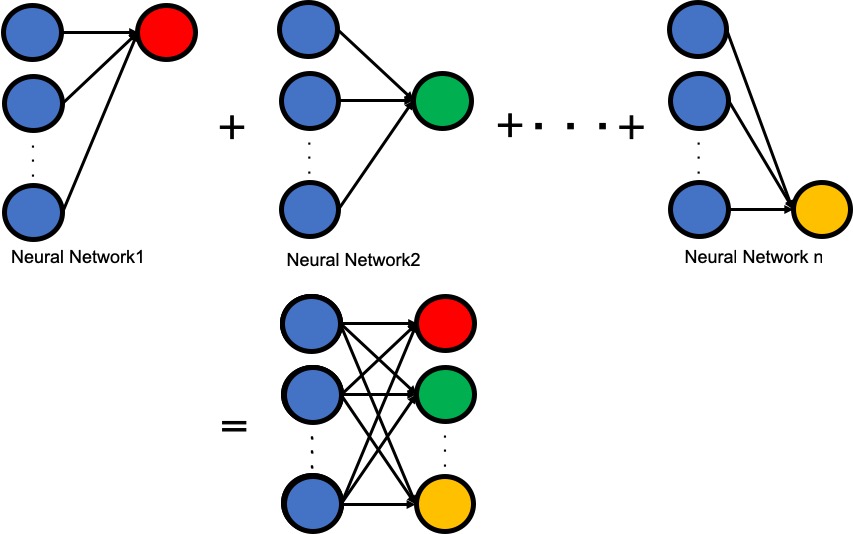
出力がベクトルになることがわかると思います。また、この式の内容より、出力の要素一つ一つは同じ入力値を使用して、重みとバイアスだけ別の値を使用していることもわかります。つまり、図1に示すように独立したニューラルネットワークをまとめているに近いわけですね。
今回は2個の同じ入力に対して、異なる4つの式を使用して生成したデータを学習させてみようと思います。使用する数式は以下に示す4つです。
- \(y=1.24x_1+1.00x_2+3\)
- \(y=0.63x_1+1.23x_2+8\)
- \(y=1.10x_1+1.90x_2-2\)
- \(y=-1.20x_1+2.12x_2+6\)
\(2\times1\)の入力に対して\(4\times1\)の出力をするので、重みの行列サイズは\(4\times2\)になります。
$$
\left(
\begin{array}{c}
y_1 \\
y_2 \\
y_3 \\
y_4
\end{array}
\right)
=
\begin{eqnarray}
\left(
\begin{array}{cc}
\omega_{ 11 } & \omega_{ 12 } \\
\omega_{ 21 } & \omega_{ 22 } \\
\omega_{ 31 } & \omega_{ 32 } \\
\omega_{ 41 } & \omega_{ 42 }
\end{array}
\right)
\end{eqnarray}
\left(
\begin{array}{c}
x_1 \\
x_2 \\
\end{array}
\right)
+
\left(
\begin{array}{c}
b_1 \\
b_2 \\
b_3 \\
b_4
\end{array}
\right)
$$
今回のプログラムでは、わかりやすさを優先するためにバッチ処理は使用していません。今後も新しいことをやる際には簡単にするためにバッチ処理を使用することはしません。では、実際にプログラムを見ていきましょう。
#インポート
import tensorflow as tf
import random
#式の定義
# 重みの定義(4*2行列)
weight=tf.Variable(tf.zeros([4,2],tf.float32))
# バイアスの定義(4*1行列)
b=tf.Variable(tf.zeros([4,1],tf.float32))
# 入力の定義(2*1行列)
x=tf.placeholder(tf.float32,(2,1))
# 教師データの定義(4*1行列)
t=tf.placeholder(tf.float32,(4,1))
# 式の設定
y=tf.add(tf.matmul(weight,x),b)
# 誤差関数の定義
loss=0.5*tf.reduce_sum(tf.square(y-t))
# 学習方法の定義(SGD)
train=tf.train.GradientDescentOptimizer(0.001).minimize(loss)
#式の定義終了
#セッションの開始
with tf.Session() as s:
s.run(tf.global_variables_initializer()) #変数の初期化
for i in range(0,10000,1): #10000回学習を行う
#教師データの生成
x_1=random.uniform(-5,+5)
x_2=random.uniform(-5,+5)
train_x=[
[x_1],
[x_2]
]
train_y=[
[1.24*x_1 + 1.00*x_2 + 3],
[0.63*x_1 + 1.23*x_2 + 8],
[1.10*x_1 + 1.90*x_2 - 2],
[-1.20*x_1+ 2.12*x_2 + 6],
]
#重みとバイアスの遷移を確認
if i%1000==0:
print("Step:",i)
print(" weight=\n",s.run(weight))
print("")
print(" bias=\n",s.run(b))
print("")
#学習の実行
s.run(train,feed_dict={x:train_x,t:train_y})
#結果の出力
print("Step:",i+1)
print(" weight=\n",s.run(weight))
print("")
print(" bias=\n",s.run(b))
<実行結果>
Step: 0
weight=
[[0. 0.]
[0. 0.]
[0. 0.]
[0. 0.]]
bias=
[[0.]
[0.]
[0.]
[0.]]
Step: 1000
weight=
[[ 1.254087 0.9983219]
[ 0.6683649 1.225721 ]
[ 1.0897695 1.900717 ]
[-1.1710865 2.1165583]]
bias=
[[ 1.9152349]
[ 5.0876913]
[-1.2441585]
[ 3.8288882]]
Step: 2000
weight=
[[ 1.2419436 1.0152545 ]
[ 0.63521856 1.2709541 ]
[ 1.0986456 1.8893709 ]
[-1.1961093 2.1505315 ]]
bias=
[[ 2.600591 ]
[ 6.927692 ]
[-1.7216988]
[ 5.200596 ]]
Step: 3000
weight=
[[ 1.2369605 0.9939987]
[ 0.6218397 1.2138892]
[ 1.1021179 1.9041814]
[-1.2060834 2.1079886]]
bias=
[[ 2.8525822]
[ 7.6042256]
[-1.8972815]
[ 5.704954 ]]
Step: 4000
weight=
[[ 1.2394005 1.0022339]
[ 0.6283901 1.2359974]
[ 1.1004176 1.8984436]
[-1.2012002 2.1244705]]
bias=
[[ 2.9455004]
[ 7.8536897]
[-1.9620262]
[ 5.890929 ]]
Step: 5000
weight=
[[ 1.2408081 0.99992055]
[ 0.63217044 1.2297862 ]
[ 1.099437 1.9000553 ]
[-1.1983823 2.1198397 ]]
bias=
[[ 2.9799323]
[ 7.9461203]
[-1.9860159]
[ 5.9598355]]
Step: 6000
weight=
[[ 1.2399153 1.0002955 ]
[ 0.62977237 1.2307936 ]
[ 1.1000592 1.8997941 ]
[-1.2001691 2.120592 ]]
bias=
[[ 2.9926233]
[ 7.980194 ]
[-1.9948623]
[ 5.985237 ]]
Step: 7000
weight=
[[ 1.2399614 0.9999469 ]
[ 0.62989676 1.2298568 ]
[ 1.1000272 1.900037 ]
[-1.2000765 2.1198928 ]]
bias=
[[ 2.9972858]
[ 7.992716 ]
[-1.9981108]
[ 5.9945664]]
Step: 8000
weight=
[[ 1.2399994 1.0000333 ]
[ 0.62999815 1.2300888 ]
[ 1.1000005 1.8999772 ]
[-1.2000017 2.1200664 ]]
bias=
[[ 2.9990015]
[ 7.9973173]
[-1.9993039]
[ 5.9980016]]
Step: 9000
weight=
[[ 1.2399902 1.0000014 ]
[ 0.62997115 1.230003 ]
[ 1.1000077 1.8999991 ]
[-1.2000208 2.1200023 ]]
bias=
[[ 2.9996436]
[ 7.998999 ]
[-1.9997399]
[ 5.9992857]]
Step: 10000
weight=
[[ 1.2400061 1.0000025]
[ 0.630018 1.2300074]
[ 1.0999954 1.8999982]
[-1.199988 2.1200047]]
bias=
[[ 2.999879 ]
[ 7.999632 ]
[-1.9999025]
[ 5.9997587]]
どうでしょうか?結果が生成した式に近似していることがわかると思います。
今日は以上
まとめ
ニューラルネットワークの出力を複数にする場合には、
- 重みに行列を入れる
- バイアスにベクトルを入れる
とする。